[암호학] Hill Cipher

알파벳 A~Z로만 이루어진 글을 주고받을 때 사용하는 암호 기술
<이론>
(암호화 과정)
1. 보내고자 하는 알파벳을 0~25에 매칭 시켜 숫자로 변환
2. 만약 홀수개의 알파벳이라면 마지막에 'X' 추가
3. 미리 준비해둔 KEY 행렬로 계산하고 modulo 연산 진행
4. 결과 값을 다시 A~Z에 매칭 시켜 암호문 완성
(복호화 과정)
1. 해당 암호문을 다시 0~25에 매칭 시켜 숫자 행렬로 변환
2. 기존 KEY의 역행렬(mod 26)로 계산하고 modulo 연산 진행
3. 결과 값을 다시 A~Z에 매칭 시켜 복호문 완성
(예시)
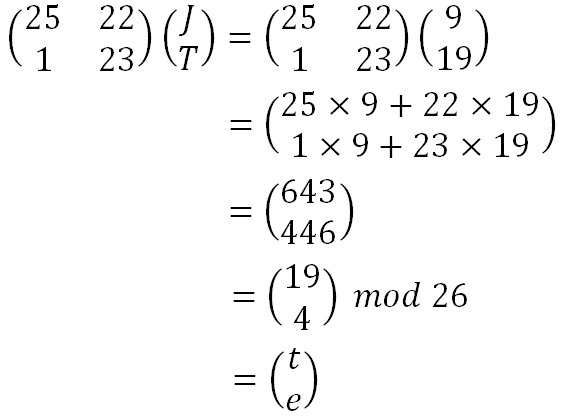
- 기존의 2x2 키 (25, 22, 1, 23)
- JT 문자열을 암호화한다고 가정하였을 때의 과정
- 최종적으로 te 암호문이 결과로 나옴
- 기존의 키의 역행렬(mod 26)을 곱하면 JT 복호문이 나옴
<구현>
(준비 과정)
1. python numpy 사용
2. GCD(ad-bc, 26) = 1을 만족하는 2x2 Key 행렬
3. 2x2 Key 행렬에 대한 역행렬 (mod 26에 대한 역행렬)
def make_inverse(list) : #mod 26에 대한 역행렬 만드는 함수
result = []
inverse = (list[0] * list[3]) - (list[1] * list[2])
if(inverse < 0) :
inverse = inverse % 26
for i in range(1,26) :
if (inverse * i) % 26 == 1 :
inverse = i
break
list[0], list[3] = list[3], list[0]
list[1] = 26 - list[1]
list[2] = 26 - list[2]
for i in range(len(list)) :
list[i] = (inverse * list[i]) % 26
return list
4. 하위 리스트 분할 함수 (보조 함수)
def list_chunk(list, n) : #n개씩 하위 리스트로 분할
return [list[i:i+n] for i in range(0, len(list), n)]
(암호화 과정)
def encryption(key, text) : #암호화 알고리즘
text_array = []
result = []
index = 0 #text에서 알파벳만 바꿔주는 index
switch = 0 #마지막 text에 x를 추가했는지 구분
for i in range(len(text)) :
if(ord(text[i].upper()) >= 65 and ord(text[i].upper()) <= 90) :
text_array.append(ord(text[i].upper()) - 65)
if len(text_array) % 2 == 1 : #text가 홀수이면 x 하나를 넣어줌
text_array.append(23)
switch = 1
text_array = np.array(list_chunk(text_array, 2))
key_array = np.array(list_chunk(key, 2))
text_array = ((text_array @ key_array) % 26) + 65 #2차원 배열 곱(내적)
for i in range(len(text_array)) :
result.append(chr(text_array[i][0]))
result.append(chr(text_array[i][1]))
for i in range(len(text)) :
if(ord(text[i].upper()) >= 65 and ord(text[i].upper()) <= 90) :
text[i] = result[index]
index += 1
if switch == 1 :
text.append(result[index])
return ''.join(text)
(복호화 과정)
def decryption(key, text) : #복호화 알고리즘
text_array = [];
result = [];
index = 0
for i in range(len(text)) :
if(ord(text[i].upper()) >= 65 and ord(text[i].upper()) <= 90) :
text_array.append(ord(text[i].upper()) - 65)
text_array = np.array(list_chunk(text_array, 2))
key_array = make_inverse(key)
key_array = np.array(list_chunk(key, 2))
text_array = ((text_array @ key_array) % 26) + 65 #2차원 배열 곱(내적)
for i in range(len(text_array)) :
result.append(chr(text_array[i][0]))
result.append(chr(text_array[i][1]))
for i in range(len(text)) :
if(ord(text[i].upper()) >= 65 and ord(text[i].upper()) <= 90) :
text[i] = result[index]
index += 1
return ''.join(text)
Testcase 1:
Key -> 5, 8, 17, 3
Plain Text -> meet me at eight o'clock
Encrypt -> OEOD OE MR SAEBF X'KJYAMP
Decrypt -> MEET ME AT EIGHT O'CLOCKX
Testcase 2:
Key -> 1, 3, 4, 5
Plain Text -> ABCDEFG+=-1234567890
Encrypt -> EFOVYLS+=-1234567890
Decrypt -> ABCDEFG+=-1234567890